Własny system transkrypcji YouTube — n8n, Whisper, NocoDB i Outline
Mam nawyk zapisywania ciekawych filmów YouTube na później. Problem w tym, że „na później" rzadko nadchodzi — a nawet gdy wrócę do filmu po tygodniu, nie pamiętam po co go zapisałem. Nie ma pełnotekstowego wyszukiwania w playlistach, nie ma streszczenia, nie ma możliwości cytowania konkretnego fragmentu.
Rozwiązanie: własny system, który pobiera transkrypt każdego interesującego mnie filmu, generuje streszczenie i zapisuje wszystko w bazie wiedzy z możliwością wyszukiwania. Kliknięcie jednego przycisku w przeglądarce uruchamia cały łańcuch.
Architektura systemu
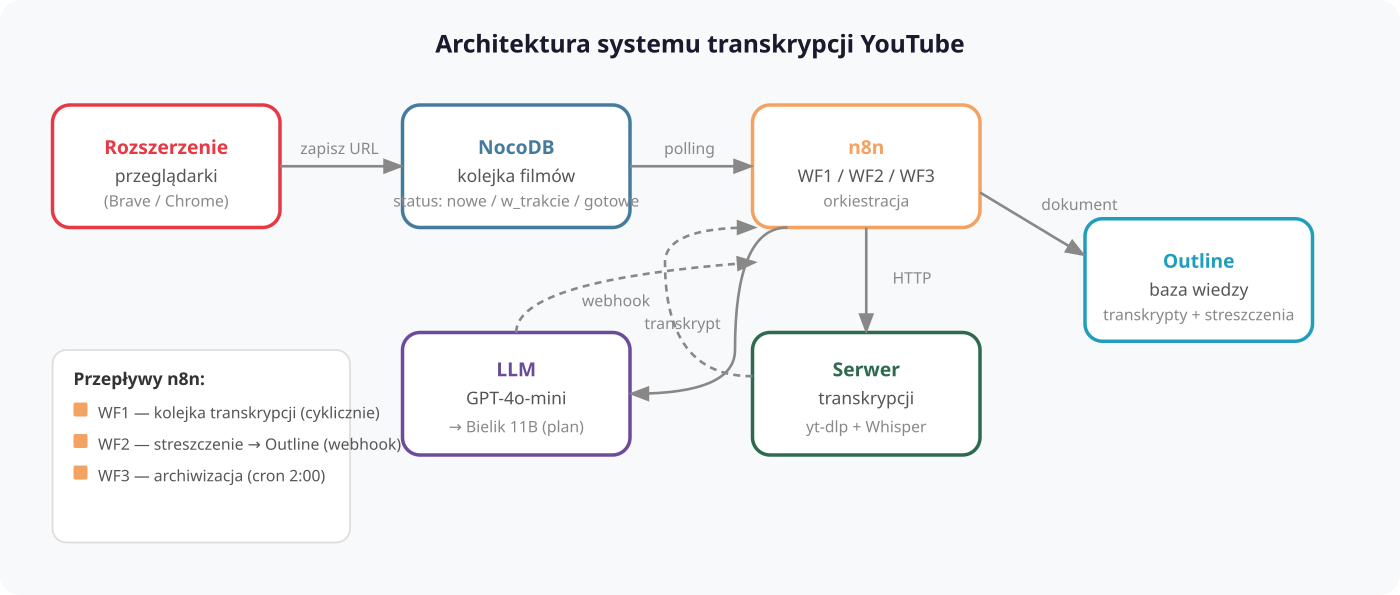
System składa się z czterech warstw, które komunikują się przez API:
Przepływ danych jest prosty: rozszerzenie przeglądarki zapisuje film do kolejki → n8n wysyła go do serwera transkrypcji → transkrypt wraca do n8n → AI generuje streszczenie → wszystko ląduje w Outline.
Komponenty
1. Rozszerzenie przeglądarki
Punkt wejścia do systemu. Gdy oglądam film na YouTube i uznam go za wart zapisania — klikam jeden przycisk.
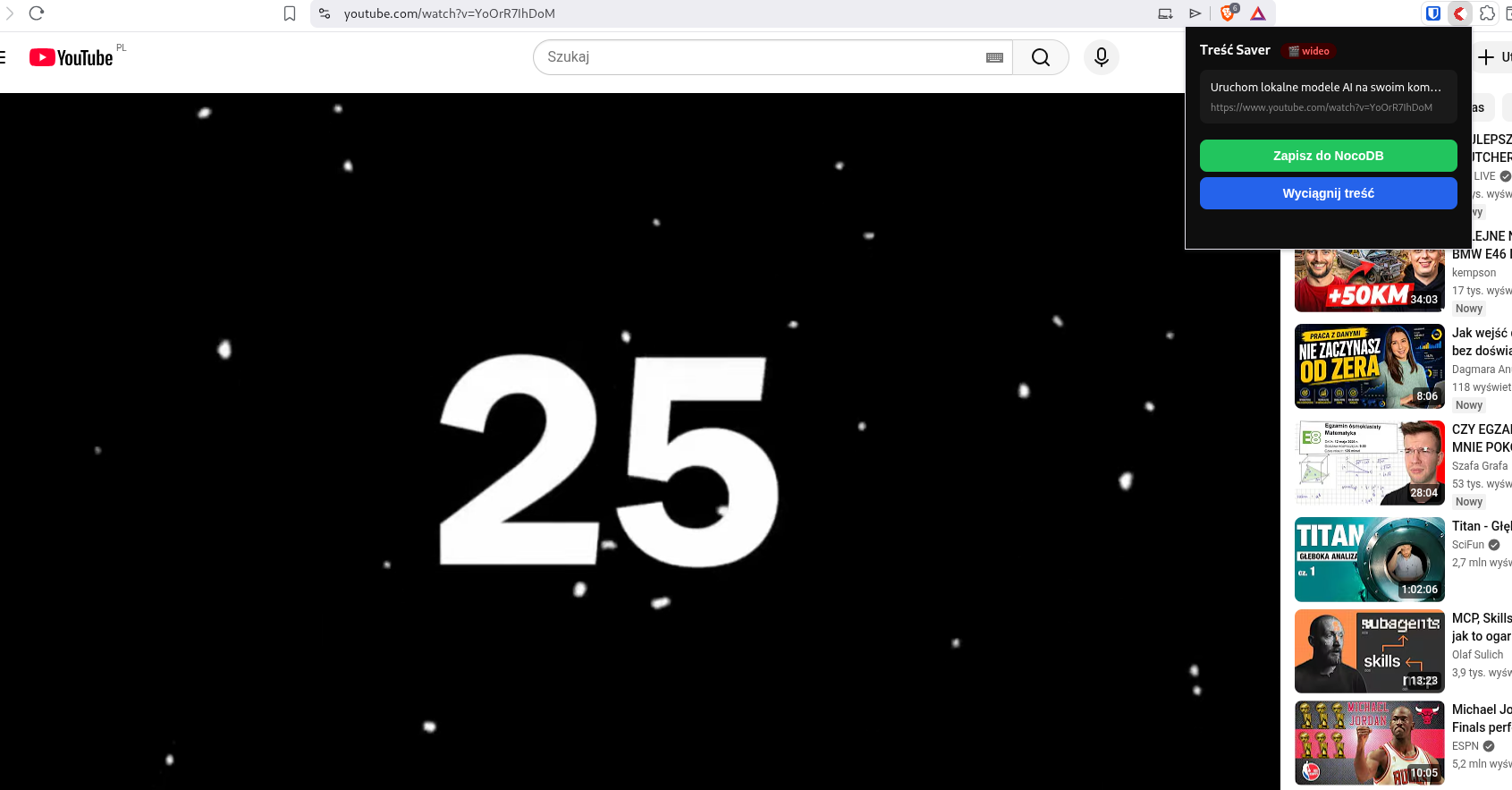
Przycisk Zapisz do NocoDB dodaje film do kolejki — tytuł, URL, miniaturkę. Nic więcej na tym etapie. Transkrypcja dzieje się w tle, asynchronicznie.
2. Kolejka i baza danych (NocoDB)
NocoDB pełni rolę kolejki zadań i jednocześnie bazy danych filmów. Każdy zapisany film ma status: nowe → w_trakcie → gotowe.
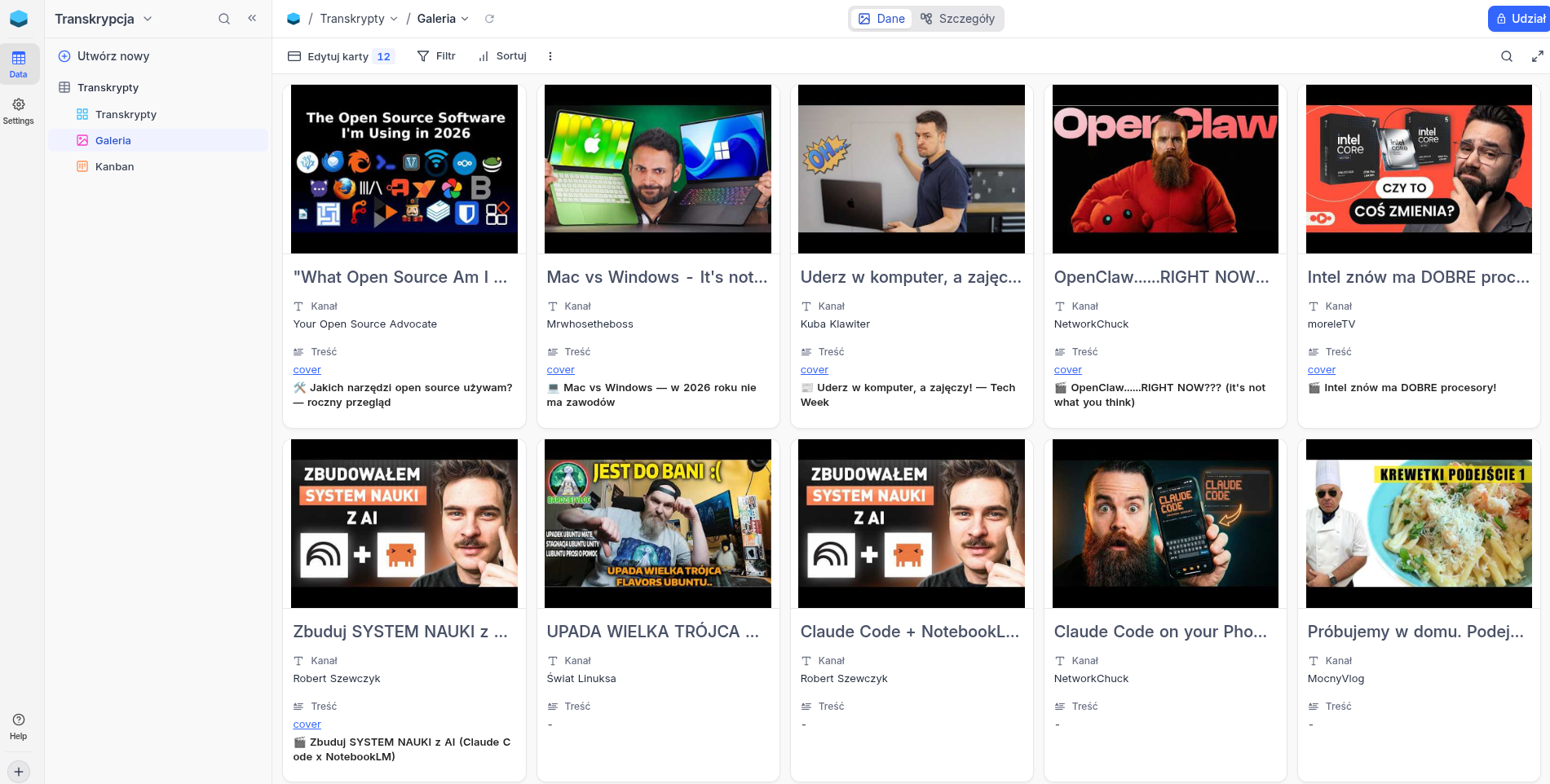
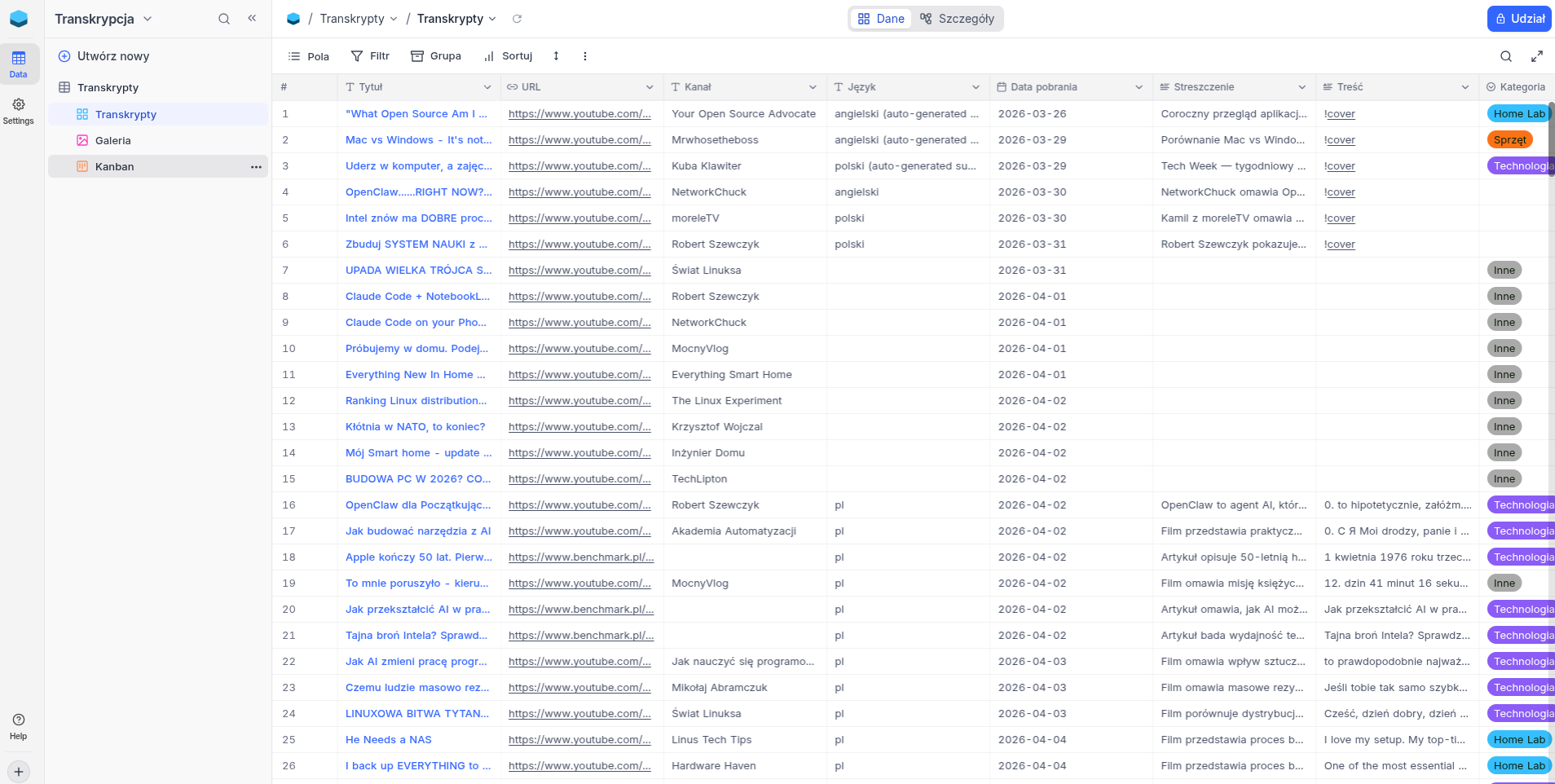
Widok galerii pozwala szybko przejrzeć co jest w bazie. Widok tabeli daje dostęp do pełnych streszczeniami i statusów.
3. Automatyzacja (n8n) — trzy przepływy
Całą logikę obsługują trzy workflow w n8n.
WF1 — Kolejka transkrypcji
Co kilka minut sprawdza czy są nowe filmy w NocoDB i wysyła je do serwera transkrypcji.
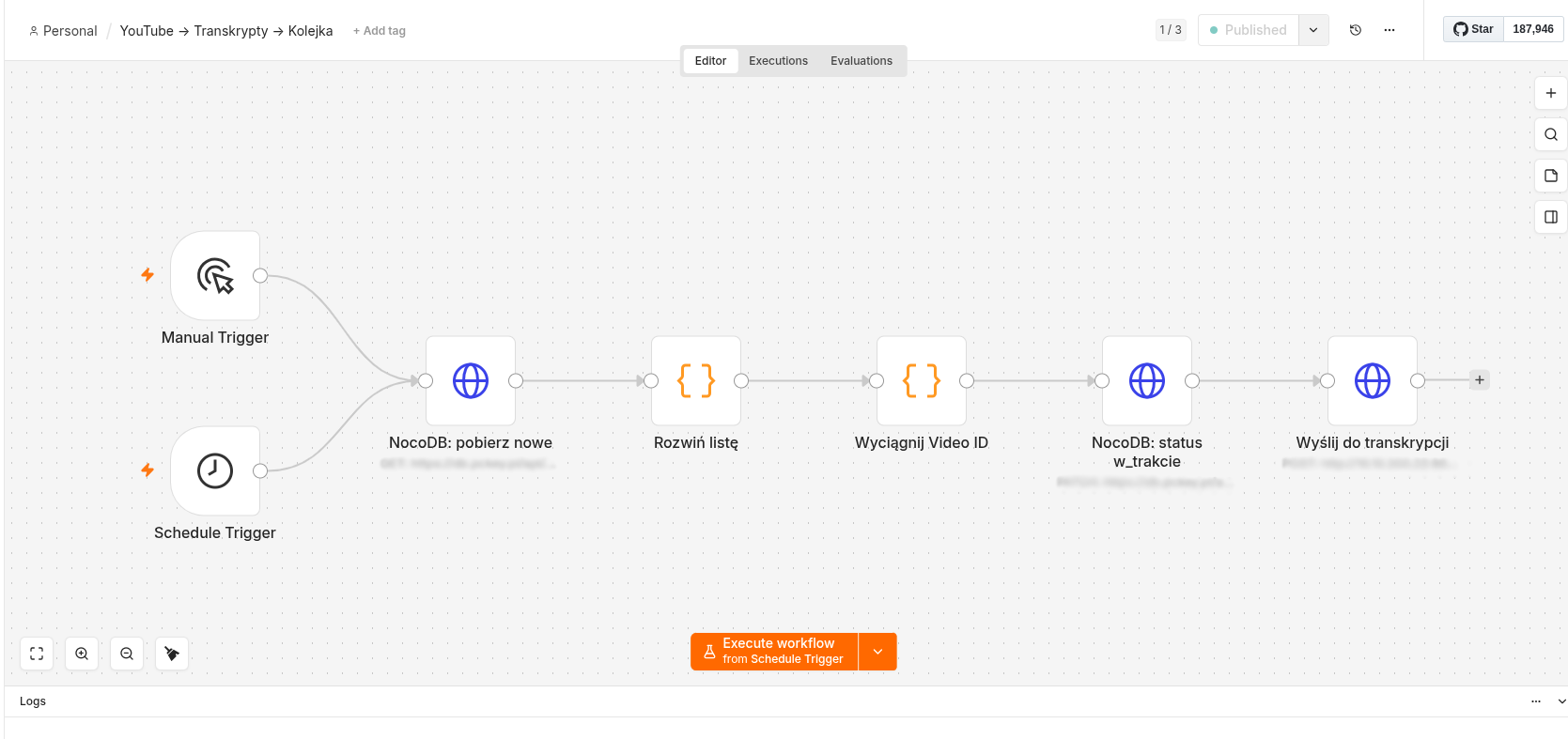
Węzły: pobranie nowych rekordów z NocoDB → wyciągnięcie Video ID z URL → zmiana statusu na w_trakcie → wysłanie żądania do serwera transkrypcji.
WF2 — Transkrypt → Streszczenie → Outline
Uruchamiany przez webhook gdy serwer transkrypcji skończy pracę. Generuje streszczenie przez AI i tworzy dokument w Outline.
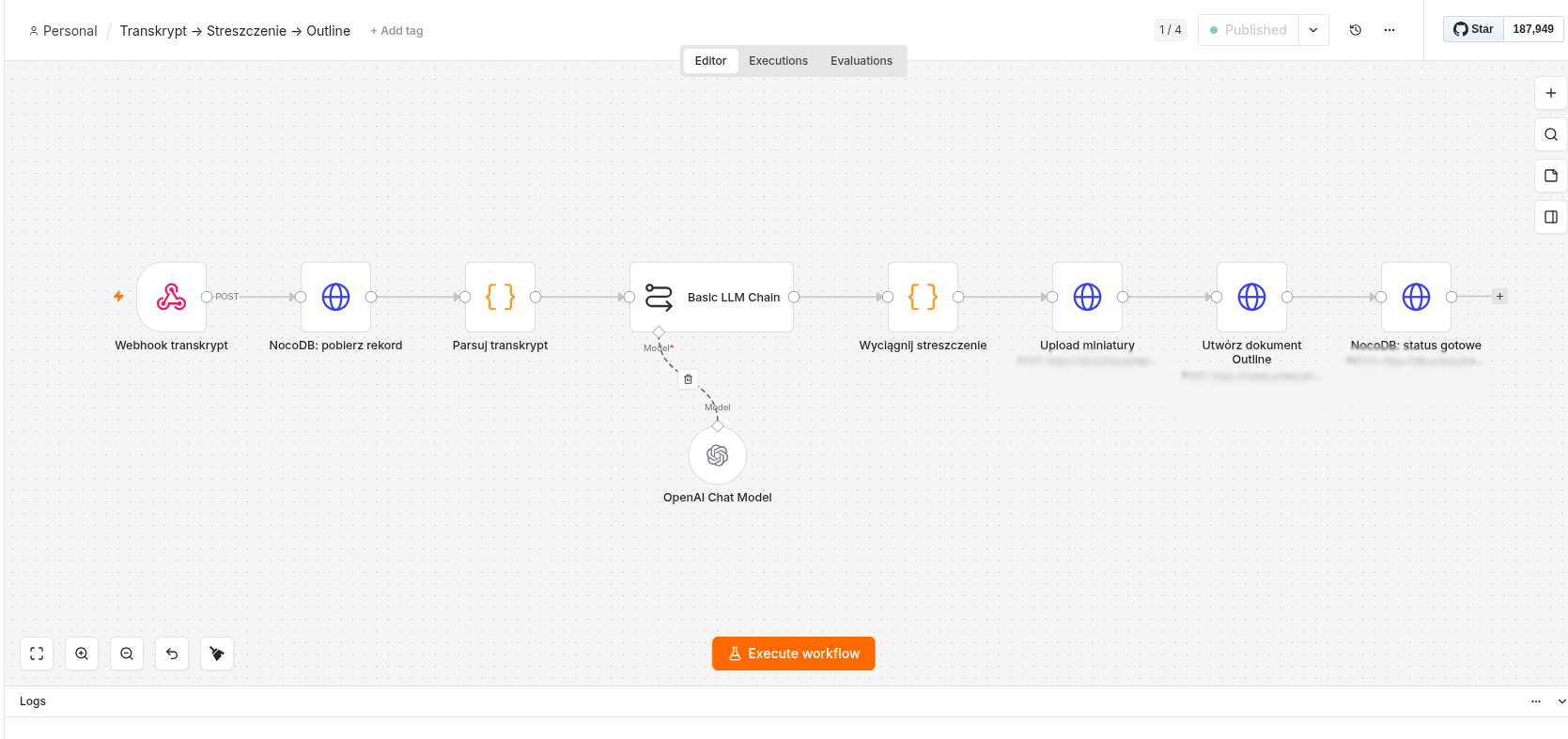
Serce systemu: transkrypt wchodzi do modelu językowego, który wyciąga kluczowe informacje w ustrukturyzowanej formie. Gotowy dokument ląduje w Outline w sekcji „Aktualności", miniaturka filmu jest automatycznie uploadowana jako okładka dokumentu.
WF3 — Archiwizacja
Codziennie o 2:00 w nocy sprawdza dokumenty w sekcji „Aktualności" i przenosi starsze niż 7 dni do folderu odpowiedniego kanału YouTube.
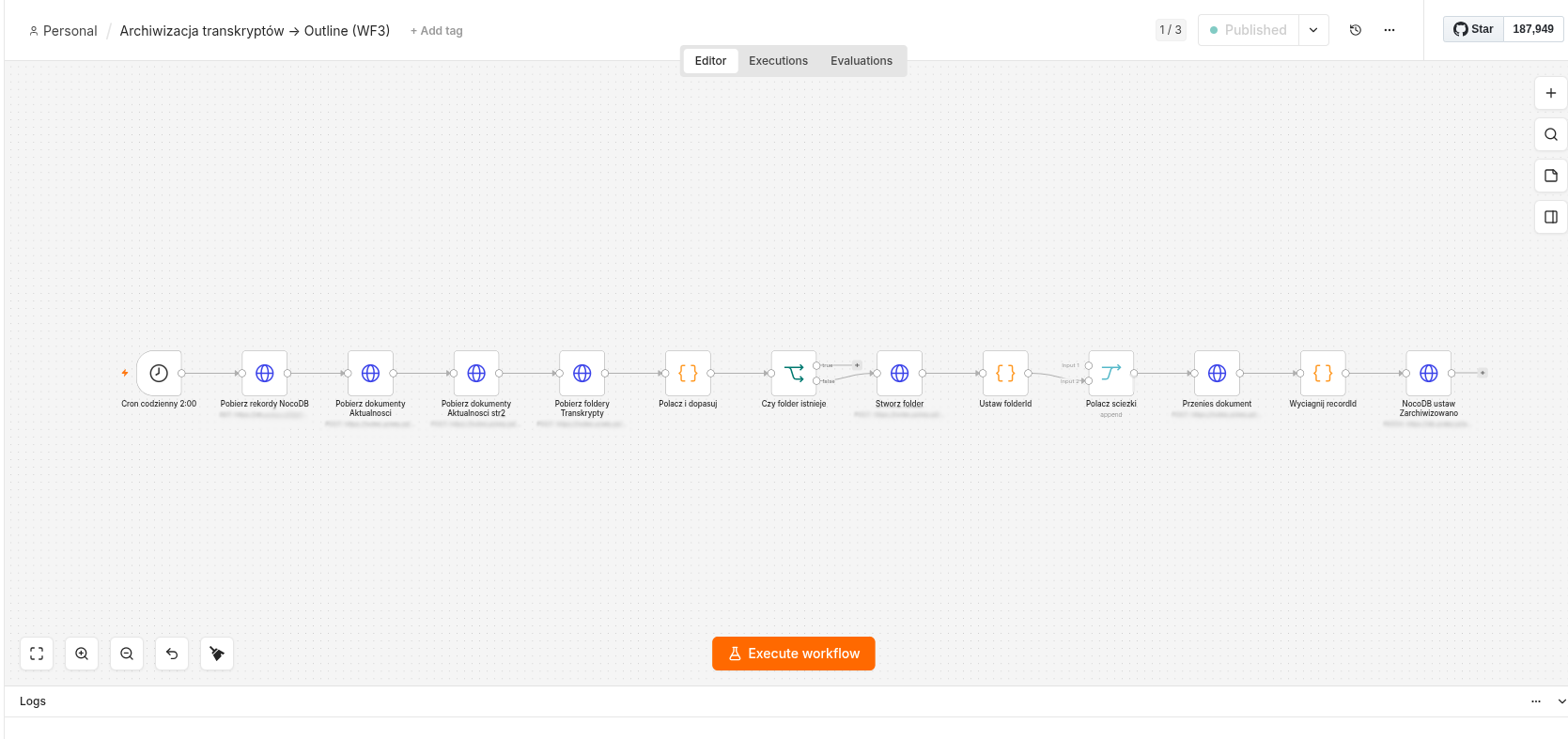
Dzięki temu sekcja „Aktualności" zawiera tylko świeże materiały, a starsze są zorganizowane według kanałów — każdy kanał ma swój folder.
4. Baza wiedzy (Outline)
Tutaj trafiają gotowe dokumenty — transkrypt z metadanymi, streszczenie w punktach, kluczowe cytaty.
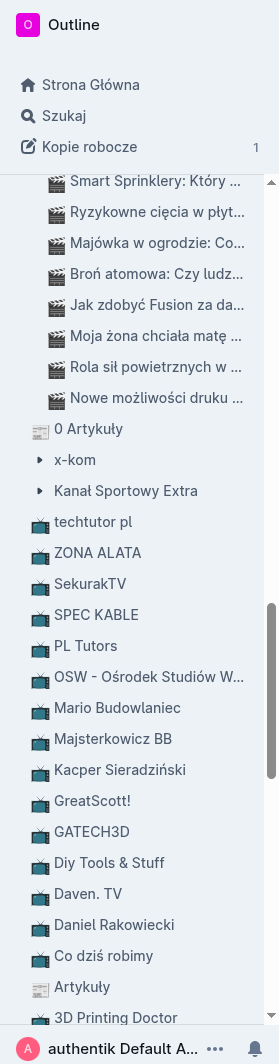
Każdy kanał YouTube ma swój folder. Pełnotekstowe wyszukiwanie w Outline działa po wszystkich transkryptach — mogę szukać po tematach, nazwiskach, technologiach.
5. Serwer transkrypcji
Serwis uruchomiony lokalnie, przyjmuje Video ID przez HTTP, pobiera film przez yt-dlp, przetwarza przez Whisper (lokalnie, na CPU) i odsyła transkrypt webhookiem z powrotem do n8n.
Całe przetwarzanie audio odbywa się na własnym sprzęcie — żaden fragment audio nie wychodzi do zewnętrznych serwisów.
Koszty
- Transkrypcja: 0 zł — Whisper działa lokalnie
- Archiwizacja i baza danych: 0 zł — NocoDB i Outline self-hosted
- Automatyzacja: 0 zł — n8n self-hosted
- Streszczenia: jedyny element z kosztem — aktualnie OpenAI API (kilka groszy za film), docelowo zastąpię lokalnym modelem
Co dalej
Następny krok to podmiana OpenAI na Bielik 11B przez Ollama. Lokalny model uruchomiony na własnym serwerze — streszczenia po polsku, zero kosztów API, pełna prywatność.
Przy odpowiednim prompcie Bielik radzi sobie z wyciąganiem strukturyzowanych informacji z transkryptów równie dobrze jak GPT-4o-mini, a prędkość generowania (~15–25 tokenów/s na CPU) jest wystarczająca gdy streszczenie nie musi być gotowe natychmiast.
System działa od kilku miesięcy i zebrał już kilkaset transkryptów. Wyszukiwanie po całej bazie zajmuje sekundy — i w końcu mogę znaleźć ten film o konkretnej technologii, który obejrzałem trzy miesiące temu.
Zobacz też
- Frigate NVR na Proxmox — instalacja i konfiguracja — kolejny self-hosted serwis na Proxmox, tym razem do monitoringu wideo z detekcją AI
Tytuł SEO: Transkrypcja YouTube — n8n, Whisper i Outline
Meta opis: Lokalny system do automatycznej transkrypcji filmów YouTube z Whisperem i n8n. Streszczenia AI, archiwizacja w Outline, zero chmury i subskrypcji.
Tagi: automatyzacja, ai-llm, n8n, self-hosting, homelab
URL slug: youtube-transkrypty-n8n-whisper-nocodb-outline
Feature image alt: Diagram architektury systemu transkrypcji YouTube z komponentami n8n, Whisper, NocoDB i Outline